I recently came across the Azure Computer Vision API. It is an image recognition engine that takes an image, tries to figure out what is on it, then returns an object with image tags, categories, a short caption text as well as other relevant information.
In this blog post, I try out that API by applying it to a new InRiver iPMC extension.
The idea
Imagine this situation.
The InRiver instance contains a lot of images and the amount is growing. It could be really great to have tags or categories on each of the images’ resource entity, so product managers can better organize and search for images. But no one would ever have the time or interest to manually go through every single image and write tags.
For this scenario, something like Azure's Computer Vision API can be applied to automate the process.
Solution outline
To support this idea, I created an entity listener extension. By doing this, instead of applying it to an inbound connector, I make a generic and encapsulated class that works equally well on automatic import (with an inbound connector) and manual upload. I have elaborated a bit further on this in my last iPMC blog post.
Also consider this: in InRiver, all images are stored as a binary file and their metadata fields are stored in corresponding resource entities. When an image is uploaded, a resource entity gets created or updated. Yet another reason to go for an entity listener extension.
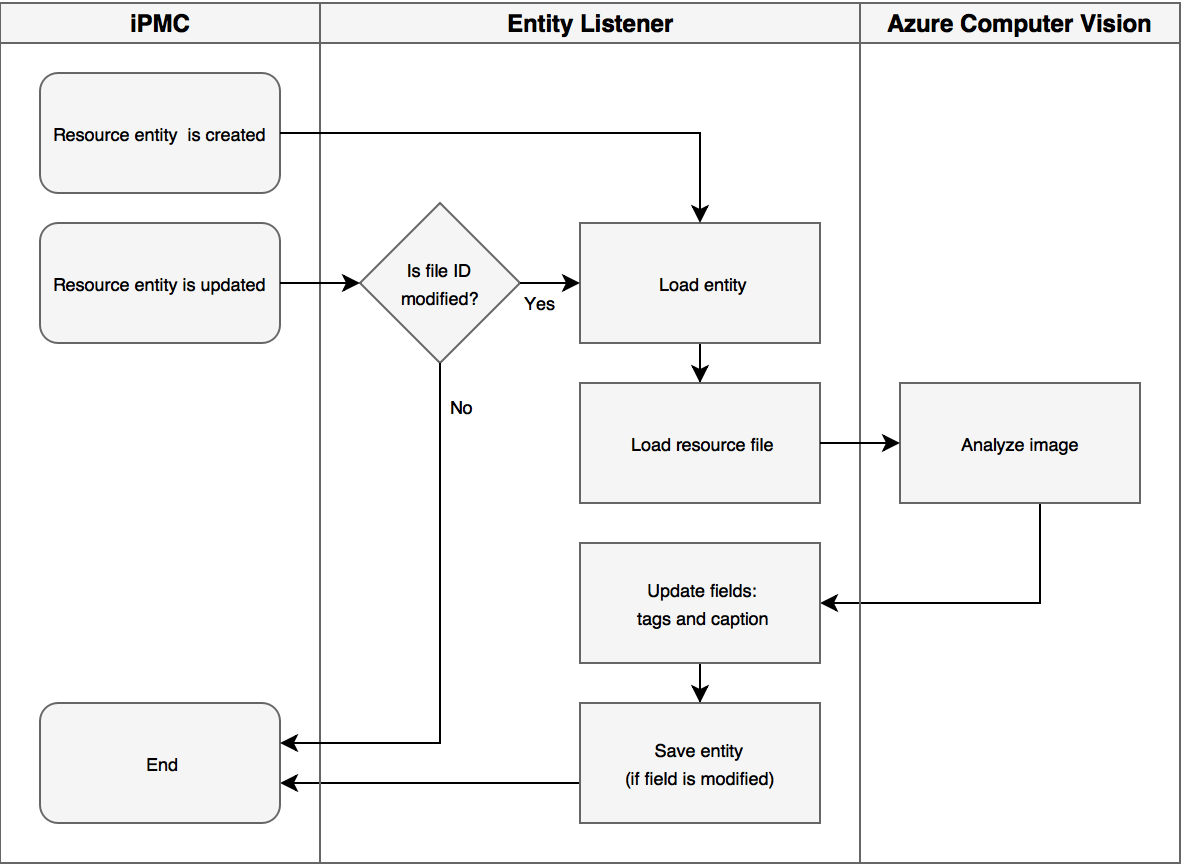
When an image is uploaded, my extension does the following:
- Loads both the resource entity and its binary data.
- Passes the binary data to the Azure Computer Vision service.
- Updates the tags and caption fields on the resource entity.
This process can also be illustrated like this.
You can take a look at the source code to my solution here. In order to run the extension, see the configuration settings in the table below.
| Settings key | Default value | Notes |
|---|---|---|
| AZURE_APIKEY | N/A | API Key for the Computer Vision API. |
| AZURE_ENDPOINT_URL | N/A | Endpoint for the Computer Vision API. |
| RESOURCE_ENTITY_TYPE_ID | Resource | Name of resource entity. |
| RESOURCE_CAPTION_FIELD_ID | ResourceCaption | Name of caption field. |
| RESOURCE_FILEID_FIELD_ID | ResourceFileId | Name of file ID field. |
| RESOURCE_TAGS_FIELD_ID | ResourceTags | Name of tags field. The field needs to be a CVL field. |
| ADD_UNKNOWN_CVL_VALUES | true | Setting that controls if unknown tags should be added to the tag CVL or if they should be ignored. |
| TAGS_MINIMUM_CONFICENDE | 0.5 | Minimum confidence (0.0-1.0) required for a caption or tag to be stored in a field. |
Sample run
To show how an analysis object can look, I ran the extension with one of my own pictures. Take a look and judge for yourself.
This is my picture.

This is the JSON object I got back from the service.
{
"categories":[{
"name":"people_",
"score":0.765625
}],
"tags":[
{
"name":"floor",
"confidence":0.9867865
},
{
"name":"building",
"confidence":0.8895089
},
{
"name":"indoor",
"confidence":0.878998
}],
"description":{
"tags":[
"fence",
"building",
"indoor",
"standing",
"young",
"man",
"holding",
"boy",
"woman",
"door",
"black",
"shirt",
"wearing",
"kitchen",
"table",
"walking",
"dog",
"board",
"room",
"oven",
"white"
],
"captions":[
{
"text":"person standing next to a fence",
"confidence":0.6120391
}]
},
"requestId":"ad83bb3a-bcf5-4dcc-81c7-6066ad078d7a",
"metadata":{
"width":747,
"height":1328,
"format":"Jpeg"
},
"color":{
"dominantColorForeground":"Brown",
"dominantColorBackground":"Grey",
"dominantColors":[
"Grey",
"Black"
],
"accentColor":"936C38",
"isBWImg":false
}
}
Some of the tags are wrong, but not that far off. For instance, it suggests I am both a man and a woman. 😀
Summary
I implemented the extension and wrote this blog post about it, simply because I wanted to try out a new technology, Azure Computer Vision API. It also sounded like a good idea in my head.
While developing the extension, I tested the API with several very different images. I noted that it sometimes was completely wrong with some of the images. In those cases, I would have liked it if I could train the engine by telling it that it was wrong.
Anyway, I do believe that this kind of technology has a great potential.