Not long ago, someone told me about this new protocol for doing web API’s, called GraphQL (Graph Query Language). It has an interesting notion of optimizing the queries and actions, which we would typically perform using several different RESTful API’s. So, naturally, I had to test it out, and I wanted to apply it to Episerver Commerce. Read on, this is really exciting!
Thinking in Graphs, not resources
A lot have already been written about the differences between GraphQL and RESTful API’s. Here is a good article about the differences.
The following is only a brief summary, comparing GraphQL to RESTful API’s.
| RESTful | GraphQL | |
|---|---|---|
| API is centered around… | Resources (each one can be accessed by unique URL). | Graphs (relations between objects). |
| Query parameters are… | Part of the URL. | Specified as query arguments, using GraphQL. |
| Number of API endpoints… | One or more per resource. | One endpoint for all queries. |
| A single request can query… | A single type of resource. | Several types of resources. |
| Querying an object returns… | All properties of an object. | Only those properties that were specified in the query. |
| An action is performed by… | Sending a request to a resource, using a specific HTTP verb. | Querying a mutation. |
In practice, with GraphQL, I can do a Single-Page Application (SPA) which makes only a single GraphQL request at load time, getting all the data necessary for rendering and interacting. It could be content like: menu items, product catalog, cart content, user profile etc. If I was using RESTful API’s instead, I would have to load all that data by issuing many separate requests to individual endpoints, in the form of different Web API controllers.
I could also do something similar with a RESTful endpoint action, returning everything needed for that application. However, then the API would not be centered around single resources, breaking the concept of resource centered API’s. That response would also return everything needed for a single page, which might be too much data for another page, should I choose to reuse the endpoint.
With GraphQL I can define all objects (resources) and teir fields, available to query. Then the client application can determine from each use case, which objects to query and which of their fields is necessary to get. This makes the API very flexible, and the responses will be as small as possible. Also, calculating dynamic fields (e.g. total tax amount or discount amount) can be skipped if those fields are not part of the query.
A scenario
In an Episerver Commerce web shop, we might need a mini cart and a large cart. In Episerver’s Quicksilver sample site, the CartController class defines two separate actions, MiniCart and LargeCart. Using GraphQL, there would be just one cart object, with numerous fields and lists of related objects (such as shipment and line item).
The fields that require calculations, would only be calculated ("resolved" is the GraphQL term) when they are part of a query. The same goes for list of related objects, e.g. only return a list of line items if they are actually queried by the client.
Querying/delivering exactly what is needed
For my demonstration I kept it simple, querying only some of the objects already defined and used in Episerver’s Quicksilver sample site. I did not make any frontend changes to that site, but tested the queries purely in the Postman and GraphiQL tools. The server-side implementation is leveraged by the GraphQL for .NET library (also available as a NuGet package).
Imagine that the site was relaunched as a SPA website, rendered using ReactJS (or similar). Maybe there would also be an app, it could be built using React Native (or similar). When that site loads, it will start loading the paged list of products, to be featured on the start page. It will also get the mini cart content. It might also check whether a customer is logged in, and get that user profile info as well. That was the scenario I envisioned, when making this demonstration.
Take a look at these requests and responses. On the left side is query and query variables; on the right is the response data.
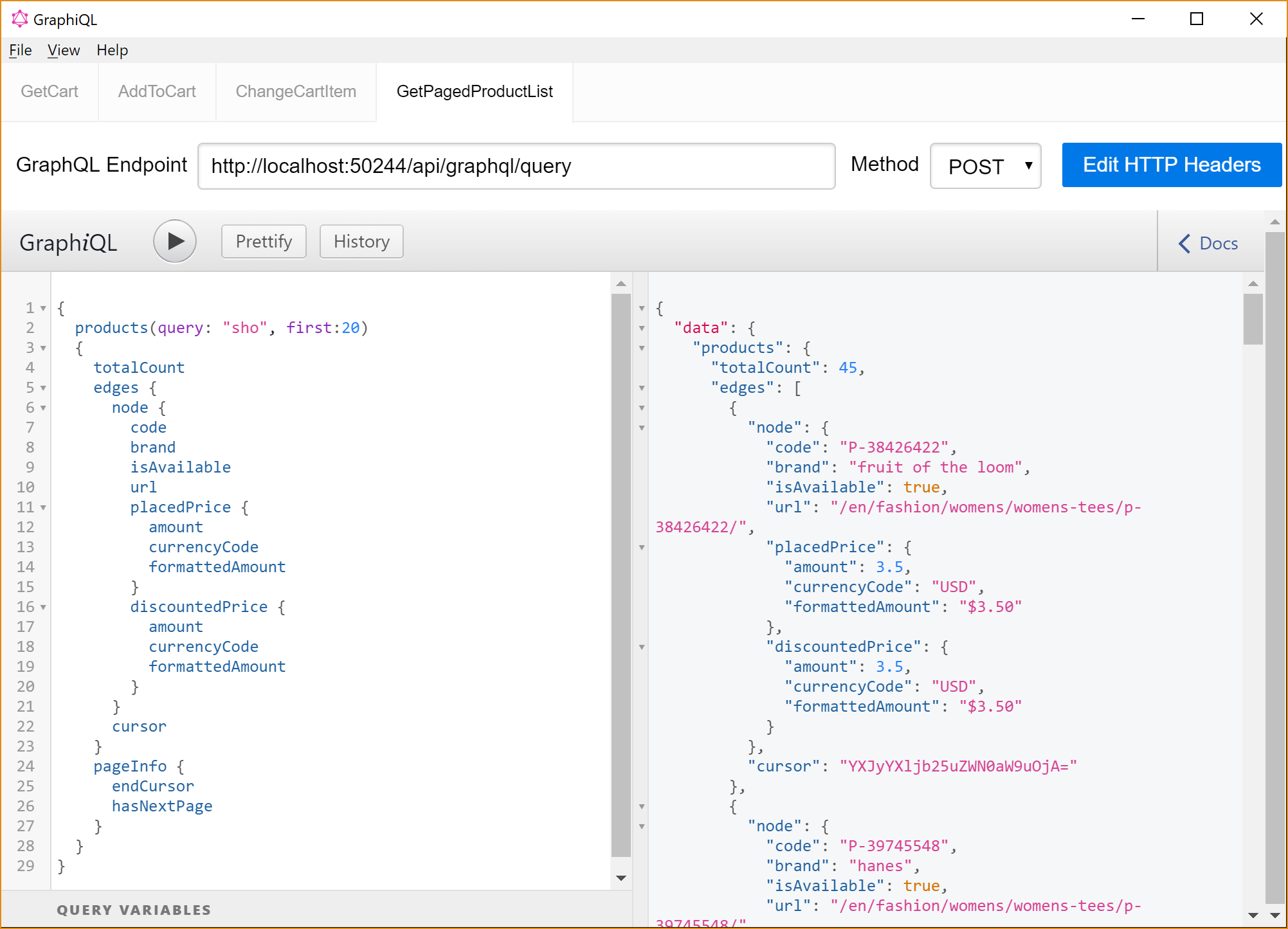
This is a query for a paged list of products, returning the first 20 products from a quick search for products starting with "sho". It could be shorts and shoes. Here are the complete JSON response.
Noticed that each item in the list has got a cursor instead of an index number? There is a good reason for that.
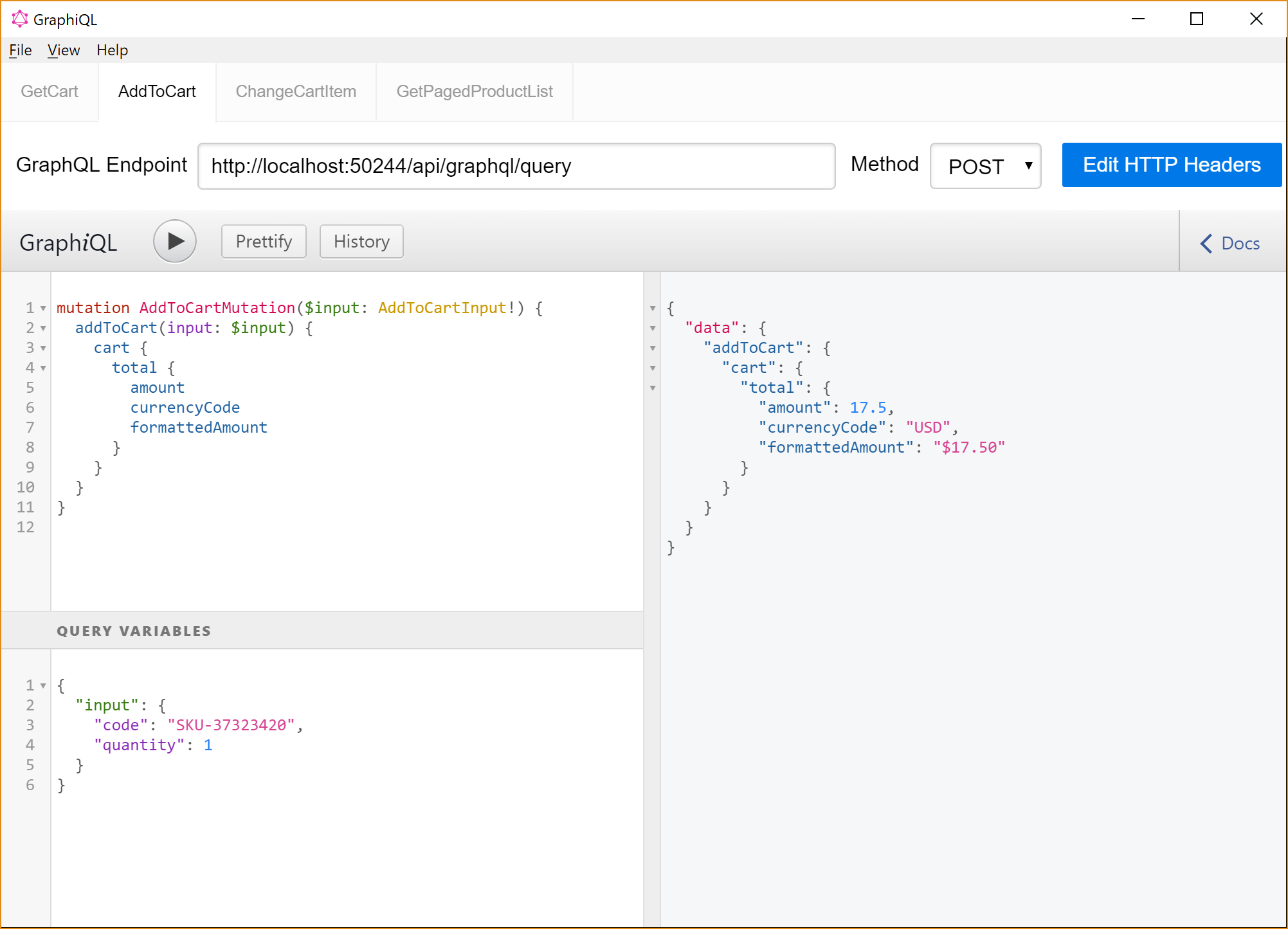
This is a mutation request for adding a single product to a shopping cart. It defines the mutation operation, consisting of the name of the mutation and the fields I want as part of the response (just like a query). Here are the complete JSON response.
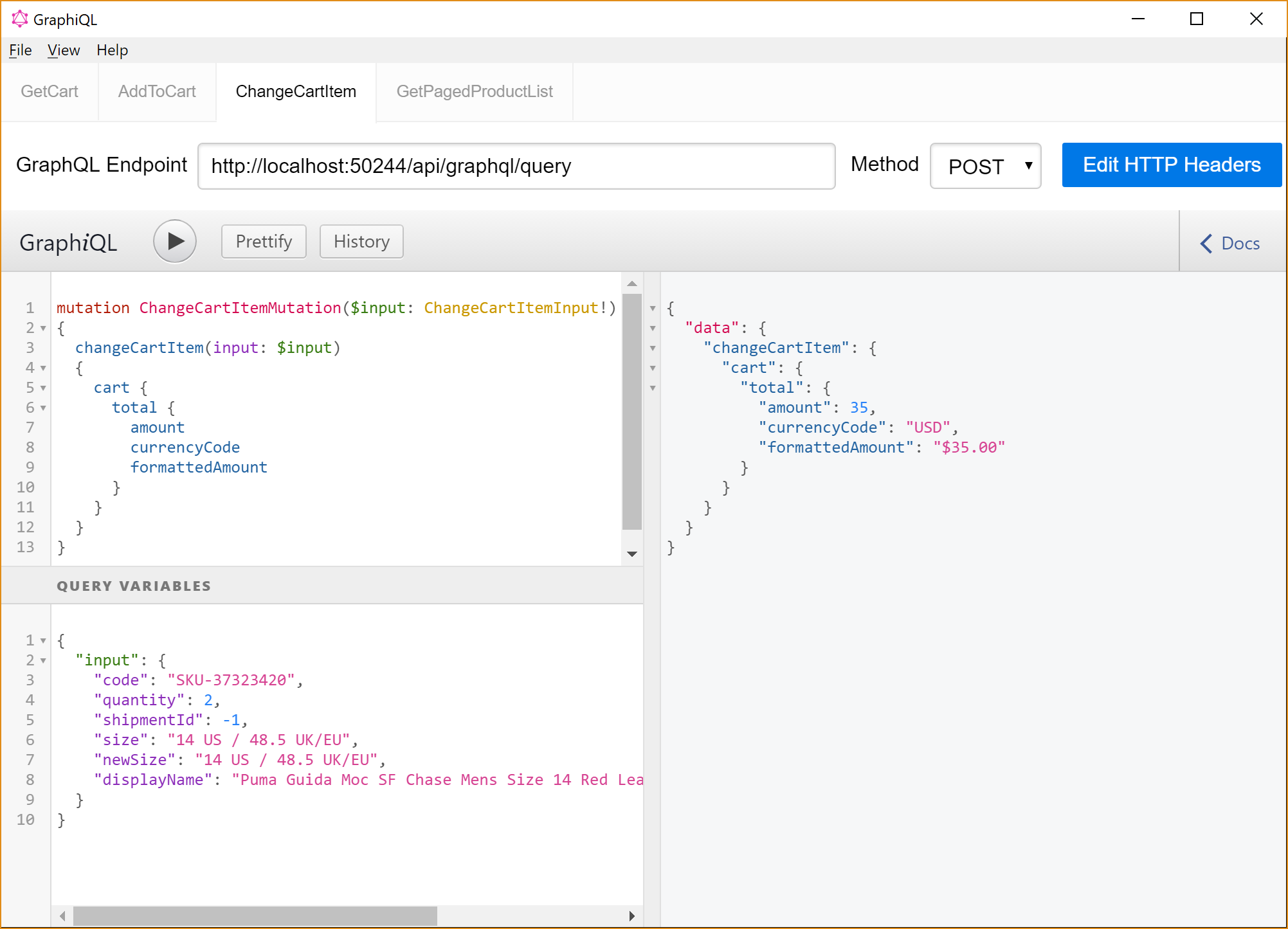
This is a mutation request for changing the line item information about a product already in a shopping cart. The query and response work just as the previous mutation. Here are the complete JSON response.
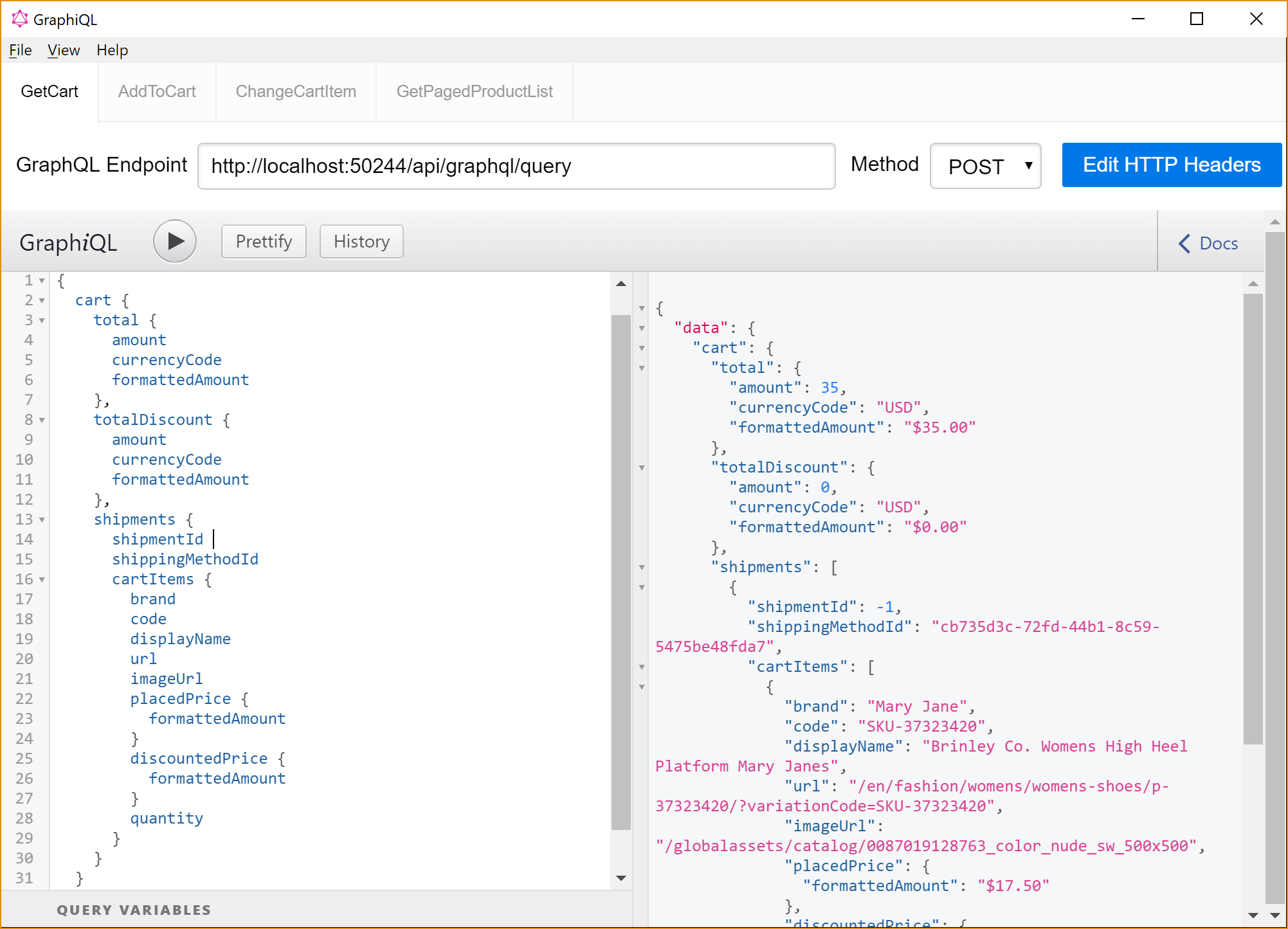
This is a query for a shopping cart returning the total amount, shipment, line items etc. It mimics the large cart view in the Quicksilver site. Here are the complete JSON response.
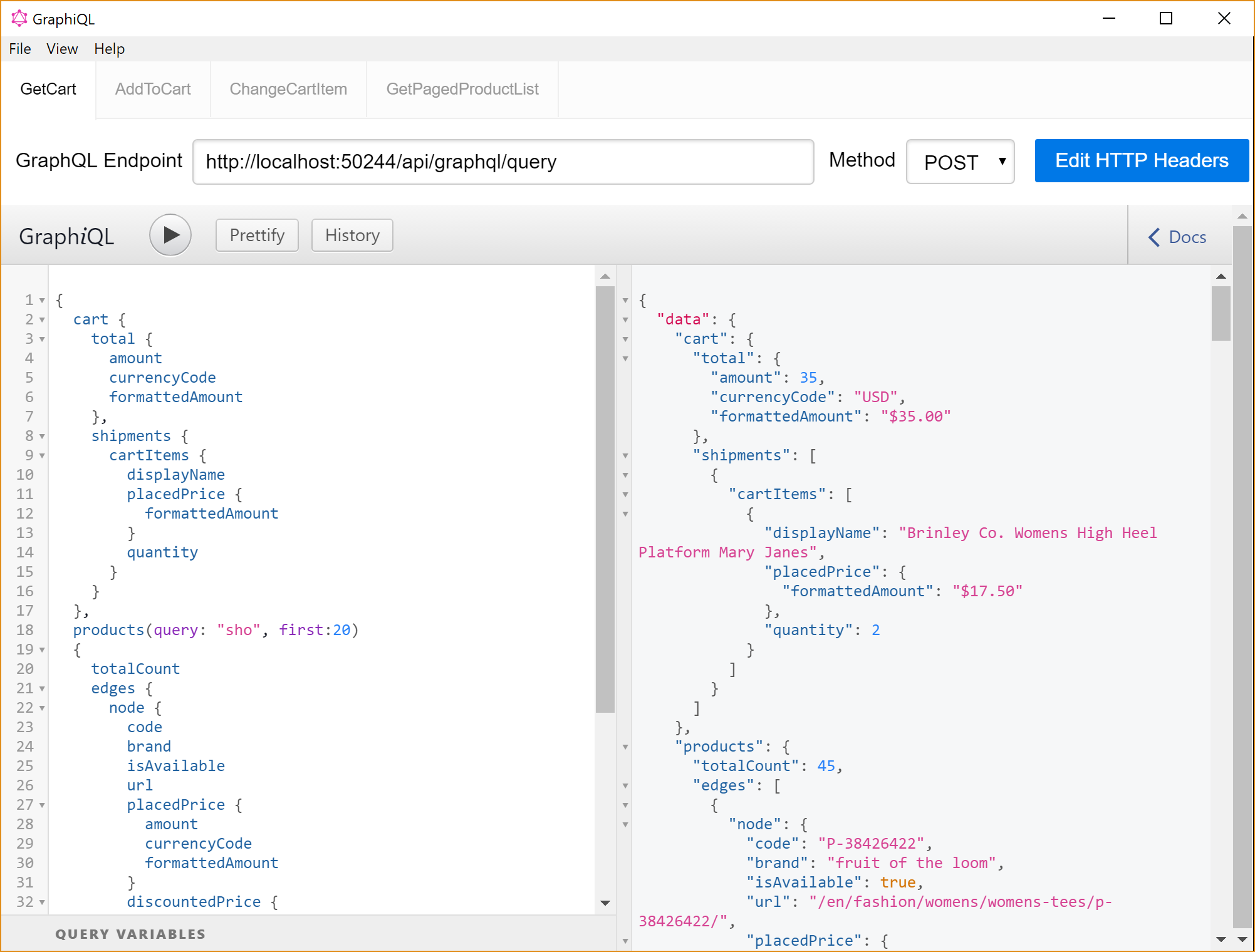
This is a combined query. It will return a mini cart view (mimicking the one in the Quicksilver site) and a paged list of the first 20 products from a quick search starting with "sho". Here are the complete JSON response.
In reality this query would be used to render a complete start page of a web shop, built with a Single-Page Application architecture.
Conclusion
Using GraphQL seems to provide solutions to a great deal of issues I am facing daily, when working on RESTful API architectures. It is interesting to see how easy it actually was to implement in an existing ASP.Net solution, even though the design concept is different and the existing code needs to be altered slightly to provide the best performance and flexibility.
However, this demonstration did only scratch the very surface of GraphQL’s features. There are many of the features I did not demonstrate, such as:
- Interfaces
- Fragments
- Unions
- Directives
- Subscriptions
- Validation
- Authorization
These features are all implemented in the GraphQL for .NET library, and I might follow up on them in the near future.